More Images


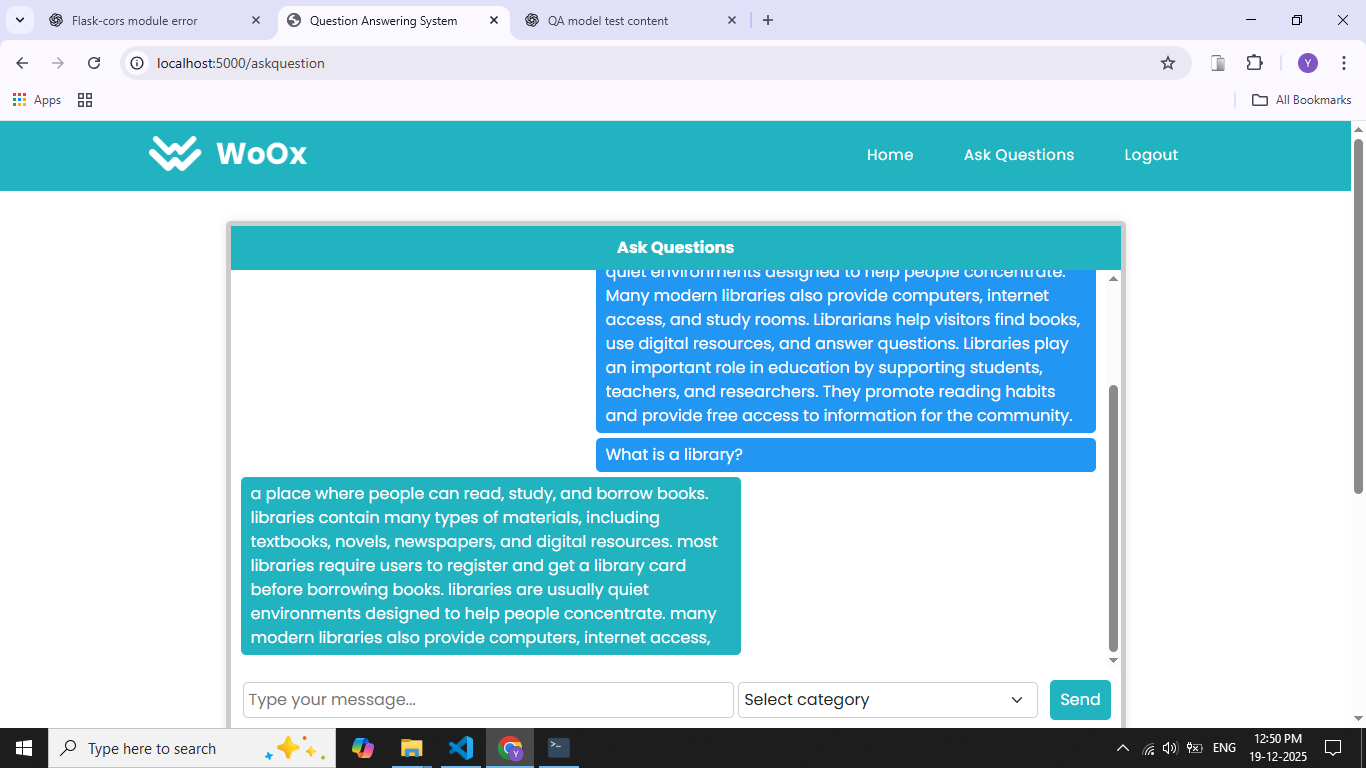
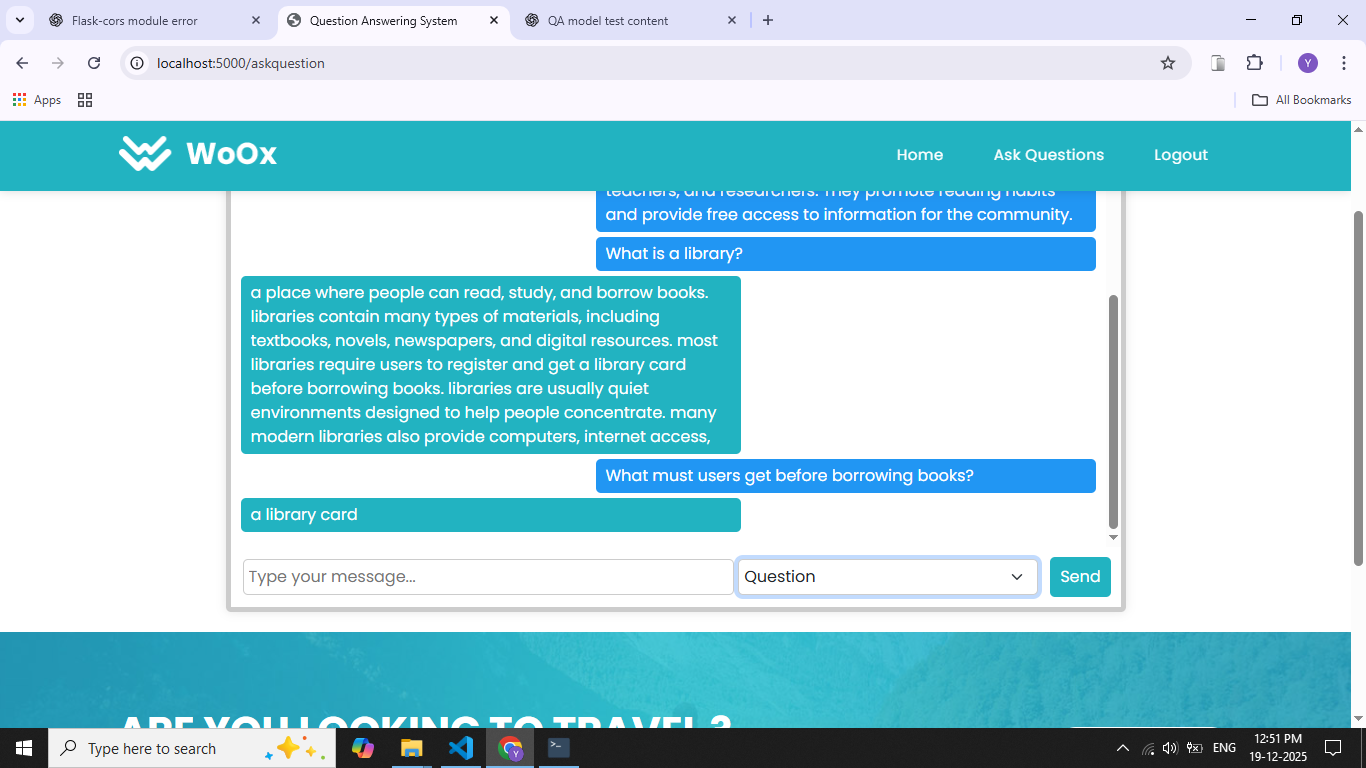
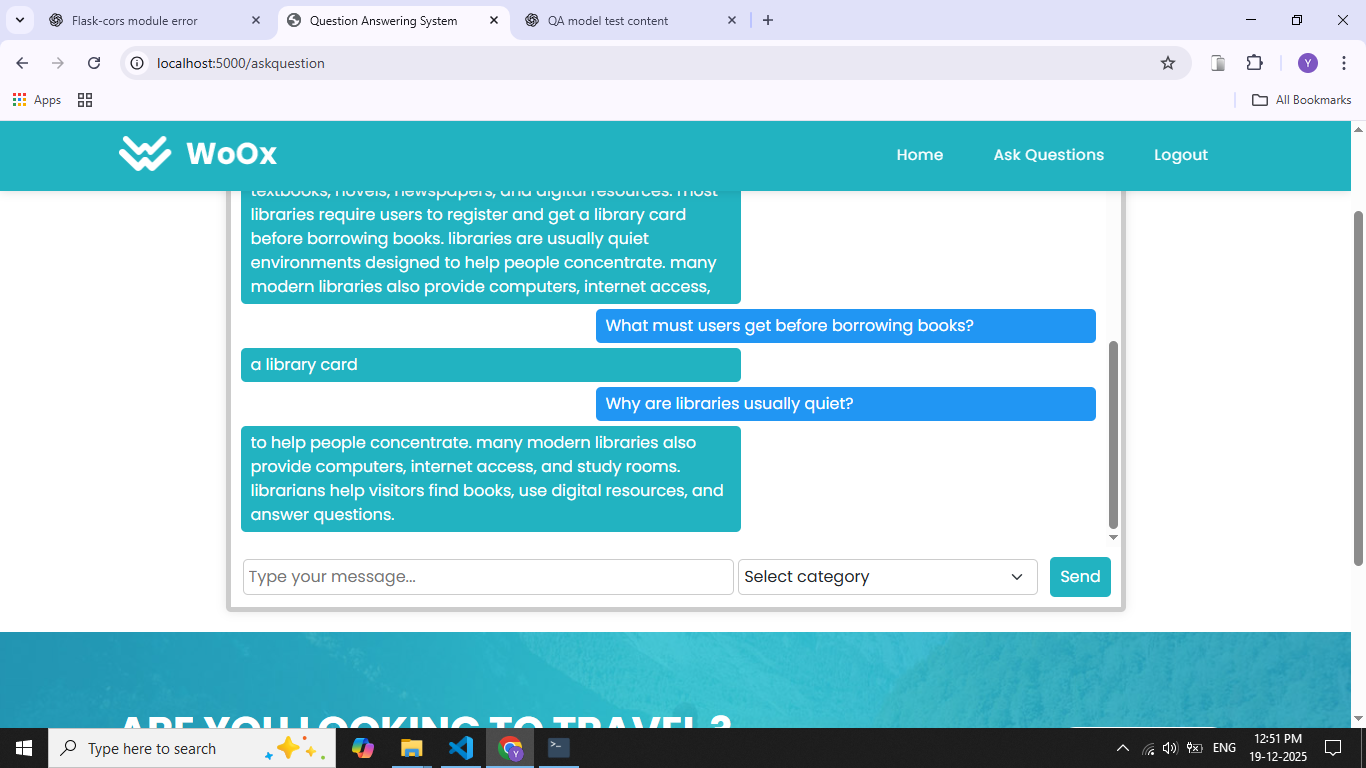
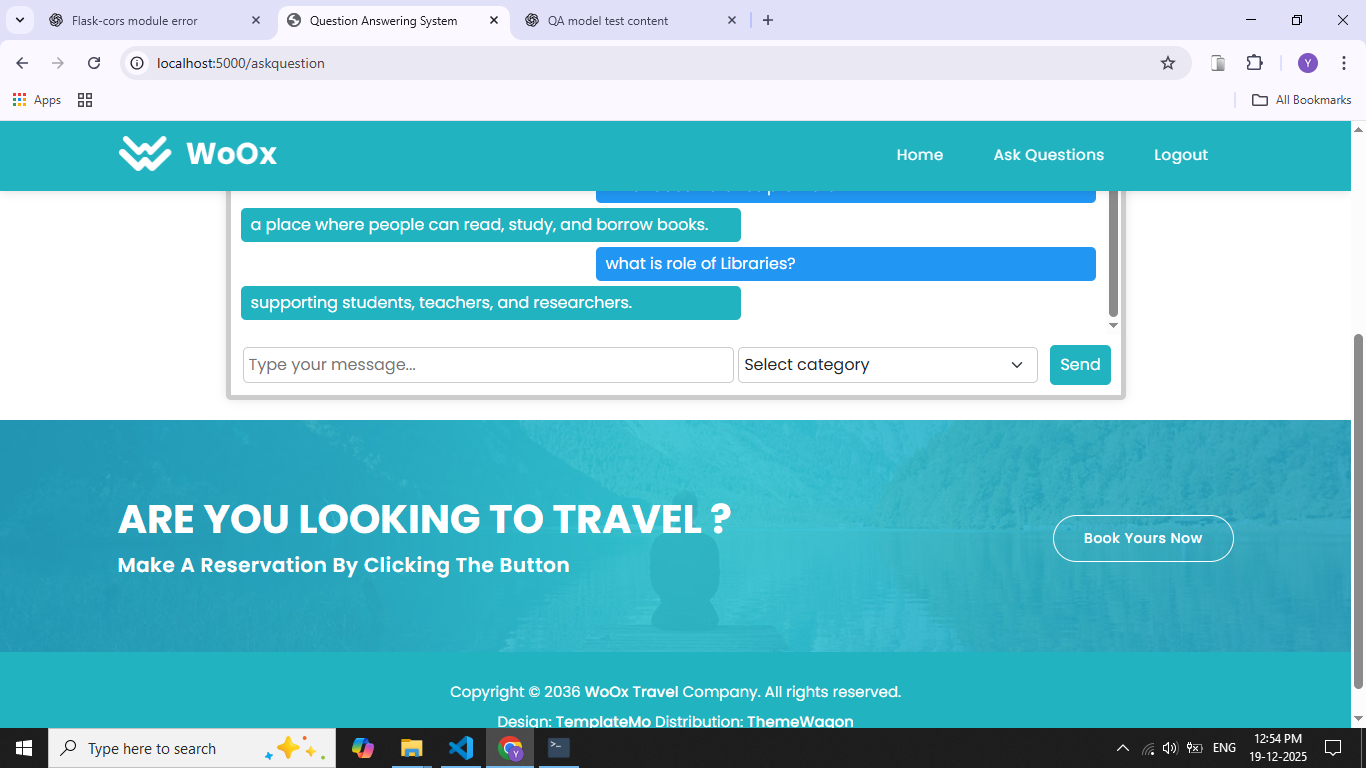
The Question Answering System Using the SQuAD Dataset is designed to automatically generate accurate answers to questions based on a given context passage. Traditional information retrieval systems return entire documents, requiring users to manually search for relevant information. This project focuses on machine reading comprehension, where the system understands context and extracts precise answers. The system is trained and evaluated using the Stanford Question Answering Dataset (SQuAD), a widely used benchmark for question answering tasks. SQuAD contains thousands of context passages paired with human-annotated questions and exact answer spans. Natural Language Processing techniques such as tokenization, embedding, and attention mechanisms are applied to process textual data. Deep learning models, including Bidirectional LSTM, Transformer-based architectures, or pretrained models like BERT, are used to learn semantic relationships between questions and context. The model predicts the start and end positions of the answer within the given passage. Performance is measured using standard evaluation metrics such as Exact Match and F1 score. This project demonstrates the effectiveness of deep learning in understanding natural language and provides a foundation for applications like chatbots, virtual assistants, and automated customer support systems.
• Modern and responsive design
• Clean and maintainable code
• Full documentation included
• Ready to deploy